
How to Train Your GenAI Dragon
For Construction and Project Management Processes


Since the public release of the first Generative Pre-trained Transformer (GPT) models in December 2022, the landscape of artificial intelligence has been radically transformed. Large Language Models (LLMs) and Generative AI have proliferated across various sectors, fostering an array of innovative use cases and applications that continues to expand. Various Open-source and licensed models are created and have begun to leave significant imprints on industries as diverse as healthcare, finance, and entertainment.
Despite recent advancements, the integration of Generative AI into everyday business processes, particularly in complex and specialized areas like construction and project management, is still limited. These fields demand the convergence of diverse domain-specific knowledge to effectively address varying project contexts with consistently high quality and precision.

A critical challenge to the broader adoption of Generative AI in these domains is not merely the accuracy or precision of these systems but their reliability, validity, and robustness. To harness the full potential of these AI models, it is imperative to either train them from the ground up, fine-tune them, or augment them with domain-specific data.
There are various methodologies for tailoring LLMs for specific tasks—each with its unique cost and utility— as below, and there are various new hybrid versions of these proposed every day.
Prompt Engineering: Crafting precise prompts to guide the model's responses.
Retrieval-Augmented Generation (RAG): Combining external data retrieval with AI generation for more informed outputs. RAG becomes even more potent when the retrieved data is structured in graph form, such as using an ontology like UPonto. This enhanced version is known as GraphRAG.
Fine Tuning: Adjusting the model with specific data to better align with tasks.
Model Training: Building a tailored model from the ground up for your unique domains
To create robust and effective LLMs to address specific tasks not only these methods should be thoughtfully combined, but also different models can be set to work with each other through innovative Flow Engineering.
These methods, like martial arts skills, enable us to unlock the vast capabilities of these models, that is the superpowers of our GenAI dragons. Despite the scientific underpinnings of these models, the practical application of these skills resembles an art form, where the behavior of billions of model parameters must be carefully orchestrated to masterfully meet specific use cases.
In this blog post, we share our insights and experience on successful customization of LLMs to address distinct work processes in construction and project management. We explore the nuanced techniques required to "Train your GenAI Dragon."
Large Language Models (LLM)?
We are all familiar with LLMs but let us first highlight few important points to understand how these AI "Night Furies" behave.
Large Language Models (LLMs) are advanced types of artificial intelligence that understand and generate human-like text by learning from vast collections of data [1], [2]. These models have billions of parameters that are finely tuned during their training, allowing them to—miraculously—capture and compress extensive knowledge into their complex structure. As a result, LLMs develop a broad understanding of language and context, making them highly versatile in handling a wide range of tasks [3].
LLMs can simplify complex ideas and create analogies to explain difficult concepts. In practical applications, LLMs can simulate scenarios, making them useful for interactive role plays such as resolving disputes between clients and contractors. You can set these models to discuss issues with each other iteratively, and hence, LLMs results can be iteratively refined.
LLMs have limitations too. They can reflect biases present in their training data, misinterpret contexts, or generate plausible-sounding but incorrect information—a phenomenon known as "hallucination." LLMs do not possess true understanding, and their responses are based on patterns and probabilities rather than deep comprehension. This necessitates careful oversight to manage biases and ensure accuracy, while opening the door to interesting debates on what is true understanding and deep comprehension anyways.
LLMs Reasoning and Understanding of Physics
Through analogical, metaphorical and associative mechanisms, LLMs are able to reason and to understand physics. The vast amounts of textual data that has gone into their training allows them to recognize patterns and associations between concepts. For instance, LLMs realize how terms like "force" and "mass" often relate to Newtonian mechanics, and their relationships with “acceleration”. This understanding is built on identifying conceptual relationships rather than genuine comprehension of experiential knowledge.
Therefore, LLMs can use analogies to explain complex physical phenomena within their real-world context. For instance, LLMs can understand and explain the physical risks of not wearing hard hats in construction sites. While this reasoning is surface-level and relies on text-derived patterns rather than a true conceptual grasp of the physical laws governing the universe, this is where the power of your GenAI dragon really lies.
Construction and Project Management
Construction and project management is a diverse and multifaceted domain with fundamental principles like planning, scheduling, budgeting, and resource allocation, and a common goal of successful execution of projects. Such a field requires a blend of technical expertise, strategic oversight, and effective communication to navigate the complexities of coordinating multiple stakeholders, adhering to timelines, and managing project technical and organizational constraints. The diversity in construction and project management stems from the variety of projects and the unique challenges each present. This is while the best practices used to navigate through these challenges are similar at fundamental levels.
LLMs are particularly useful in such domains. They can streamline processes by generating detailed project plans, incorporating historical data, assisting in risk management, and facilitating communication across diverse teams with the goal of increasing productivity, maintaining high quality, and reducing human errors. They help project managers by providing quick and contextually relevant responses, drafting reports, and even aiding in decision-making through data-driven insights, making them invaluable tools in the modern construction and project management landscape.
How to Train Your GenAI Dragon
The adaptation of Large Language Models (LLMs) to meet the specific needs of different industries is progressing swiftly. This is due to the varying and often complex requirements across sectors, prompting the development of several techniques to customize these powerful models. Each method comes with its own set of benefits and computational demands, with multiple hybrid methods being proposed each day. Below, we outline the four primary approaches, arranged from the least to the most computationally intensive.
1. Prompt Engineering
Prompt engineering transforms LLM performance by optimizing input without modifying model parameters [4]. This practice, akin to programming for LLMs, involves strategically crafting and formatting prompts to guide the models in interpreting questions and generating precise, relevant responses. Initially met with skepticism among technical experts, prompt engineering has become a crucial skill, bridging the gap between complex model development and user-friendly AI applications. To master prompt engineering, users can use several effective strategies, such as ensuring clarity and specificity, providing contextual cues, iteratively refining prompts, and using few-shot learning to align responses closely with user intentions.
Few-shot learning is when the model is provided with a few examples of the desired task or output within the prompt itself. This helps the model understand and generate the type of response expected without extensive retraining or fine-tuning.
2. Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) is a technique that significantly boosts the capabilities of LLMs by incorporating external knowledge sources into their response generation process [5]. RAG combines the creative potential of LLMs with the precision of information retrieval systems. It works by employing a retrieval mechanism to fetch relevant data from a predefined dataset—be it documents, articles, or databases—and then integrating this information into the model's responses [6]. When you ask ChatGPT to summarise or answer your questions based on a document, you are enacting a RAG interaction.
The most remarkable advantage of RAG is its ability to provide LLMs with up-to-date and accurate information particularly when circumstances are changing, such as providing the model with the latest data and reports when executing a project. This latest data may as well be the results of other AI discriminative and predictive AI models. Hence, RAG allows the Generative AI to work with Discriminative AI, i.e., other advanced forms of machine learning!
GraphRAG for Complex Knowledge Integration
GraphRAG, or Graph-based Retrieval-Augmented Generation, is an innovative extension of RAG that leverages the power of graph-based knowledge representation. This methodology integrates LLMs with graph databases, which structure information in nodes and edges, allowing for more sophisticated and interconnected knowledge retrieval. GraphRAG enables LLMs to access and synthesize information from complex data relationships and hierarchies, providing richer and more nuanced responses.
At EPM Research, we extensively utilise GraphRAG to increase the functionality of LLMs. By utilizing ontologies like UPonto, which are designed to structure project data intricately, we aim to enhance LLMs' understanding and manipulation of project-related information [7]. GraphRAG's ability to handle complex interrelationships within data makes it an ideal tool for applications where the integration of diverse and detailed datasets is essential for effective responses, such as in construction and project management.
3. Fine-Tuning
Fine-tuning involves adjusting the internal parameters of a pre-trained model, a process that demands substantial computational power, and is a powerful methodology to enhance model performance for specific tasks [8].
LLMs are trained on extensive, general datasets to build a robust linguistic foundation. In the fine-tuning phase, the model is further tuned on smaller, domain-specific datasets containing specialized terminology and relevant documents. This targeted training sharpens the model's understanding of contextual aspects within specific domains, boosting accuracy and relevance for particular applications. For instance, in construction and project management, fine-tuning could involve training the model on datasets containing construction project case studies, risk management protocols, and compliance guidelines. This enables the model to more accurately interpret unique aspects of construction projects, like detailed risk assessments and project scheduling.
Fine-tuning itself has various intricacies to consider, but on the highest level, it can be done as Task-Specific, Domian Specific, or for Data Augmentation with each requiring different approaches.
4. Training LLM Models
Training an LLM from scratch for a specialized domain is both costly and complex due to several factors. Firstly, the data requirements are immense. General LLMs are trained on datasets containing hundreds of billions of tokens, and gathering a comparable amount of high-quality, domain-specific data (say in construction and project management domain) would be challenging and time-consuming, while the model may lack contextual understanding and analogical reasonings that it may gain by capturing a general corpus of textual data. Moreover, the computational cost of training such models is significant. For instance, training GPT-3 was estimated to cost several million dollars in compute resources alone [9].
Given these high costs, the previous methods discussed such as fine-tuning an existing model on domain-specific data appears to be the efficient and practical approach. Those methods leverage strong pre-trained models, which have already learned general language patterns and can be adapted to specific tasks or domains with relatively smaller datasets and lower computational costs.
Show Me How
To illustrate how Prompt Engineering, Retrieval-Augmented Generation (RAG), and Fine-tuning (excluding GraphRAG) can synergize to create a GenAI risk advisor, here is a preliminary example of a customized model.
This model takes the project scope, breaks it down into tasks, identifies their risks, and then creates a comprehensive risk register. In this example, the model is applied to Toronto’s notorious Eglinton Crosstown LRT project. By fine tuning the model with extensive data on urban Light Rail Transit (LRT) infrastructure projects, it identified groundwater issues, underground utilities, and community concerns as the top three risks for the project.
This example is quite general, and the tasks these AI "Dragons" must master to run a project are diverse in both knowledge and skills. Indeed, there are ways to set specialized models to interact with each other to achieve broader goals. Here is now the Flow Engineering.
Flow Engineering: Foxes and Hedgehogs
"The fox knows many things, but the hedgehog knows one big thing," wrote the ancient Greek poet Archilochus. The idea was expanded by many thinkers and philosopher, such as Isaiah Berlin to categorize thinkers and their worldviews: foxes, draw on a wide variety of experiences and strategies, but hedgehogs, interpret the world through a singular, overarching principle.
In artificial intelligence, this idea may find compelling parallels. AI models can be trained as 'foxes'—adaptive systems capable of handling diverse tasks by integrating vast amounts of data and adjusting to different scenarios. Conversely, 'hedgehog' models specialize deeply in a narrow field, mastering specific, well-defined problems with precision. When these two types of AI work in tandem they enable a holistic approach to solving complex tasks that require both broad adaptation and focused expertise.
Flow Engineering is an innovative and iterative approach where multiple AI agents, particularly LLMs work together and interact with their environment and each other to complete tasks efficiently [10]. This involves decomposing complex tasks into smaller, more manageable and learnable steps. The tasks are then distributed among several specialized AI agents, each specialized in different aspects of the problem, and then passed through channels by generalist agents tasked to collect information, summarize, and report. Flow Engineering significantly enhances the accuracy and performance of the AI systems. This collective intelligence mirrors how different teams or departments might work together in a business setting to address various components of a project.
To continue with our “How to Train Your Dragon” analogies, the figure below shows a high-level flow structure of how different models, i.e., dragons, can work together to prepare the materials needed for a risk management workshop. The system generates a draft risk register for the project based previous projects data that amounts to considerable quality and productivity gains for the human risk team.
Each dragon is customized through fine-tuning and prompt engineering with their appropriate knowledge and been connected to a graphical database of project historical data through GraphRAG to ensure high efficiency and accuracy in their designated tasks. Note the Risk Assessor and Risk Manager can disagree through a feedback mechanism that enacts further conversation between them. Stay tuned for more on this in our future posts.
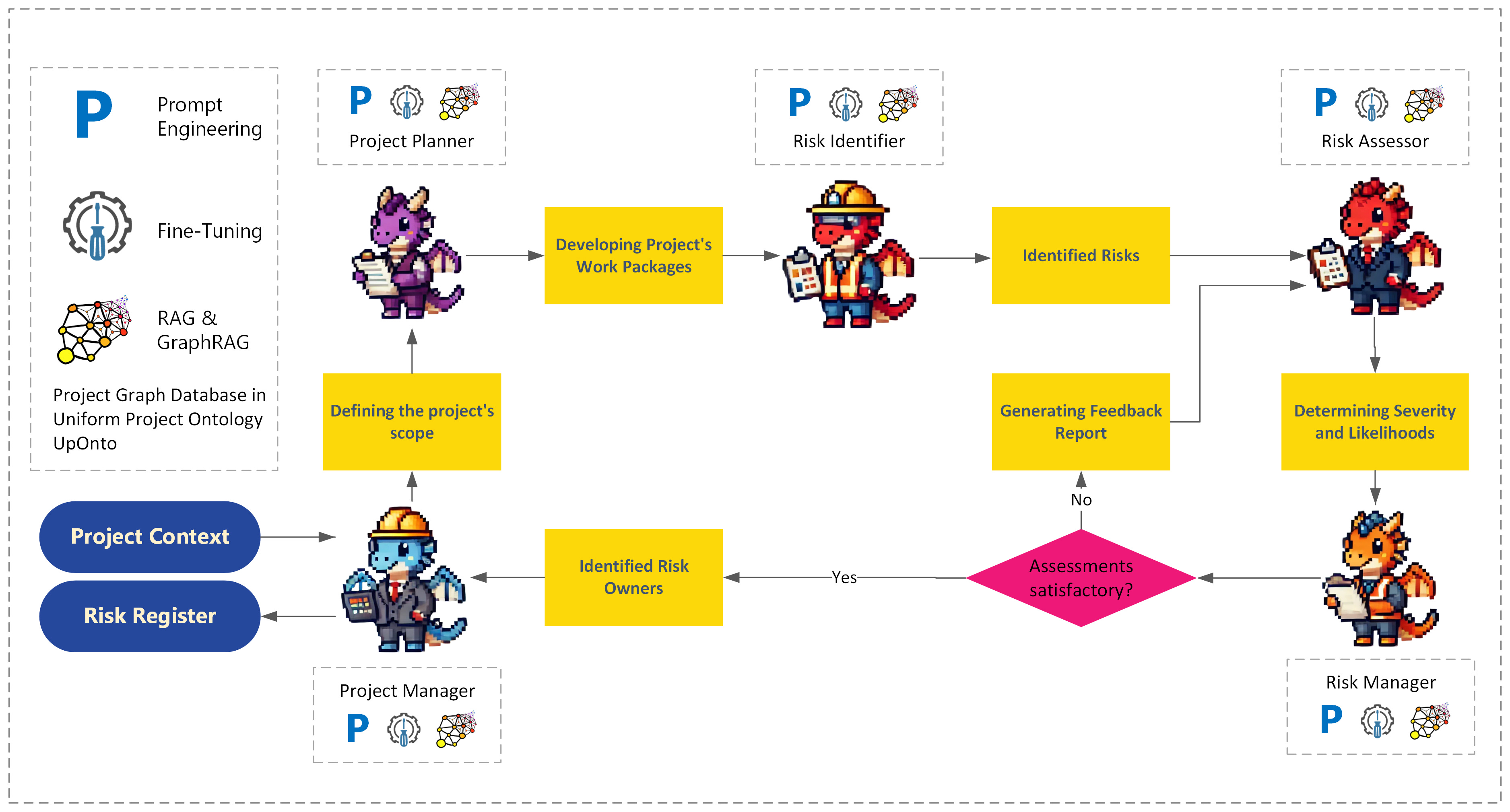
Another fascinating way to understand this process is by drawing a parallel to Daniel Kahneman's theories of System 1 and System 2 thinking from his seminal work, "Thinking, Fast and Slow." Kahneman describes System 1 as the fast, intuitive, and automatic mode of thinking, while System 2 is slower, more deliberate, and analytical [11]. We believe similar structures can be reproduced through flow engineering.
Conclusion
Selecting the optimal method for enhancing LLMs in construction and project management greatly depends on the specific challenges and requirements of a given task. Each method discussed—i.e., Prompt engineering, Fine-tuning, RAG, and Model Training—offers unique advantages that can be leveraged individually or in combination to address different aspects of work processes. Moreover, models can be set to work with each other through Flow Engineering.
For tasks requiring quick responses or where the information needed is well within the scope of the LLM’s training, prompt engineering is highly effective. It allows users to guide the model to generate specific outputs without the need for retraining. Conversely, when a deeper understanding of specific construction terms and processes is necessary, fine-tuning can adapt an LLM to respond more accurately to specialized queries by aligning it closer to domain-specific language and scenarios. However, this method is resource-intensive, requiring substantial training data and computational power. It also risks overfitting to the training data, which might reduce the model's effectiveness on other tasks.
In scenarios where accuracy and the incorporation of the latest data are crucial—such as compliance with the newest safety regulations or standards—RAG proves invaluable. By pulling in up-to-date external data, RAG ensures that the information provided by the LLM is both current and highly relevant, making it ideal for dynamic environments where regulations and conditions frequently change. It offers richer responses with less data needed than fine-tuning.
For complex decision-making processes that require varied inputs and multi-faceted analysis, deploying multiple AI agents can be advantageous. This approach allows the system to handle multiple aspects of a problem simultaneously, mirroring more complex human decision-making processes and providing a holistic view that single models or simpler methods cannot achieve. Nonetheless, it introduces complexities in integration and management, requires higher computational resources, and may incur increased maintenance costs. Conflicts between agents' outputs can also arise if not properly managed.
In practice, a combination of these methods provides the best results. For instance, an LLM could be fine-tuned with industry-specific data, use prompt engineering to ensure user-friendly interactions, and employ GraphRAG to integrate the latest external data or machine learning models’ results for enhanced decision-making accuracy. In more complex scenarios, multiple AI agents might work to manage different data streams or perform specialized analyses. Each agent may benefit from prompt engineering, RAG, and fine-tuning methods.
Access Our Research and GenAI Customized Models
While our resources are limited, we would be delighted to implement our Generative AI models and workflow in your organization for free!
It is important to note that our Generative AI customized models can learn and operate locally in an isolated environment, eliminating the need to connect to the open cloud. This ensures the utmost respect for data security and governance concerns within your organization. Our research focuses on understanding how to combine these techniques to train GenAI models tailored for various workflows and business processes. Consequently, the trained models and the insights they gain from your data remain exclusively yours.
Moreover, we invite you to share your insights on how Generative AI can revolutionize construction and project management processes. Participate in our survey to help us identify the areas best suited to benefit from this cutting-edge technology. Your feedback will play a crucial role in shaping our research and the future of AI in our industry.
References
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., and Sutskever, I., “Language models are unsupervised multitask learners,” OpenAI Blog, vol. 1, no. 8, p. 9, 2019.
Brown, T. et al., “Language models are few-shot learners,” Adv. Neural Inf. Process. Syst., vol. 33, pp. 1877–1901, 2020.
Arcas, B. A. y, “Do large language models understand us?,” Daedalus, vol. 151, no. 2, pp. 183–197, 2022.
Si, C. et al., “Prompting gpt-3 to be reliable,” ArXiv Prepr. ArXiv221009150, 2022.
Zhang, Y. et al., “Siren’s Song in the AI Ocean: A Survey on Hallucination in Large Language Models,” ArXiv Prepr. ArXiv230901219, 2023.
Lewis, P. et al., “Retrieval-augmented generation for knowledge-intensive nlp tasks,” Adv. Neural Inf. Process. Syst., vol. 33, pp. 9459–9474, 2020.
Zangeneh, P., and McCabe, B., “Ontology-based knowledge representation for industrial megaprojects analytics using linked data and the semantic web,” Adv. Eng. Inform., vol. 46, 2020, doi: 10.1016/j.aei.2020.101164.
Naveed, H. et al., “A Comprehensive Overview of Large Language Models.” arXiv, Dec. 27, 2023. Accessed: Jan. 21, 2024. [Online]. Available: http://arxiv.org/abs/2307.06435
“How Much Does It Cost to Train a Large Language Model? A Guide | Brev docs.” Accessed: Jun. 22, 2024. [Online]. Available: https://brev.dev/blog/llm-cost-estimate
Ridnik, T., Kredo, D., and Friedman, I., “Code Generation with AlphaCodium: From Prompt Engineering to Flow Engineering.” arXiv, Jan. 16, 2024. Accessed: Jun. 08, 2024. [Online]. Available: http://arxiv.org/abs/2401.08500
Zangeneh, P., “In Honor of Daniel Kahneman and What his Work Means for Project and Risk Management,” EPM Research. Accessed: Jun. 22, 2024. [Online]. Available: https://epmresearch.substack.com/p/in-honor-of-daniel-kahneman-and-what
Notes
If you wish to refer to this article, please use the following citation format:
Zangeneh, P. and Ghorab, Kh. (2024), “How to train your GenAI Dragon for Construction and Project Management Processes”, EPM Research Letters, https://epmresearch.substack.com/p/how-to-train-your-genai-dragon
 | A guest post by
|